Epigenetic Pacemaker Usage
The Epigenetic Pacemaker, EPM, fits a linear model for each input methylation site and then minimize the observed error across sites by updating the epigenetic state of the input samples. While the fit epigenetic state the has a linear relationship with the input methylation sites under the EPM the trait of interest may not. In this way the EPM can directly modeling non-linear trait, epigenetic relationships. The initial guess for the epigenetic state is generally the phenotype of interest; ie. an EPM model is trained with age associated sites and chronological ages to model epigenetic aging. The EPM is fit using sites of interest, and no site selection is performed during model fitting. This approach differs from penalized regression models commonly employed for epigenetic trait modeling, which perform site selection and model fitting simultaneously.
Example Data
Test data has been adapted from GSE74193. The data were generated by Jaffe et al. 2015 as part of a study on DNA methylation patterns in the frontal cortex during development. The data have been separated into training and testing sets by stratified sampling of sample ages. Sampled data was then processed by selecting sites correlated with aging.
The data can be loaded by importing and calling the data importation function. The returned data contains a list of GEO sample identifiers, CpG sites, sample age information, and an array of methylation beta values.
# import the data retrieval class
from EpigeneticPacemaker.ExampleData.DataSets import get_example_data
# retrieve the training and testing data
test_data, train_data = get_example_data()
# unpack the training and testing data
test_samples, test_cpg_sites, test_ages, test_methylation_values = test_data
train_samples, train_cpg_sites, train_ages, train_methylation_values = train_data
Site Selection
Given a phenotype of interest and a methylation array the EPM is fit with trait associated CpG sites. In this example Pearson correlation is used to select age associated sites by selecting sites with an absolute correlation coefficient above a user specified threshold.
import numpy as np
def pearson_correlation(meth_matrix: np.array, phenotype: np.array) -> np.array:
"""calculate pearson correlation coefficient between rows of input matrix and phenotype"""
# calculate mean for each row and phenotype mean
matrix_means = np.mean(meth_matrix, axis=1)
phenotype_mean = np.mean(phenotype)
# subtract means from observed values
transformed_matrix = meth_matrix - matrix_means.reshape([-1,1])
transformed_phenotype = phenotype - phenotype_mean
# calculate covariance
covariance = np.sum(transformed_matrix * transformed_phenotype, axis=1)
variance_meth = np.sqrt(np.sum(transformed_matrix ** 2, axis=1))
variance_phenotype = np.sqrt(np.sum(transformed_phenotype ** 2))
return covariance / (variance_meth * variance_phenotype)
# get the absolute value of the correlation coefficient
abs_pcc_coefficients = abs(pearson_correlation(train_methylation_values, train_ages))
# return list of site indices with a high absolute correlation coefficient
training_sites = np.where(abs_pcc_coefficients > .85)[0]
Helper Functions
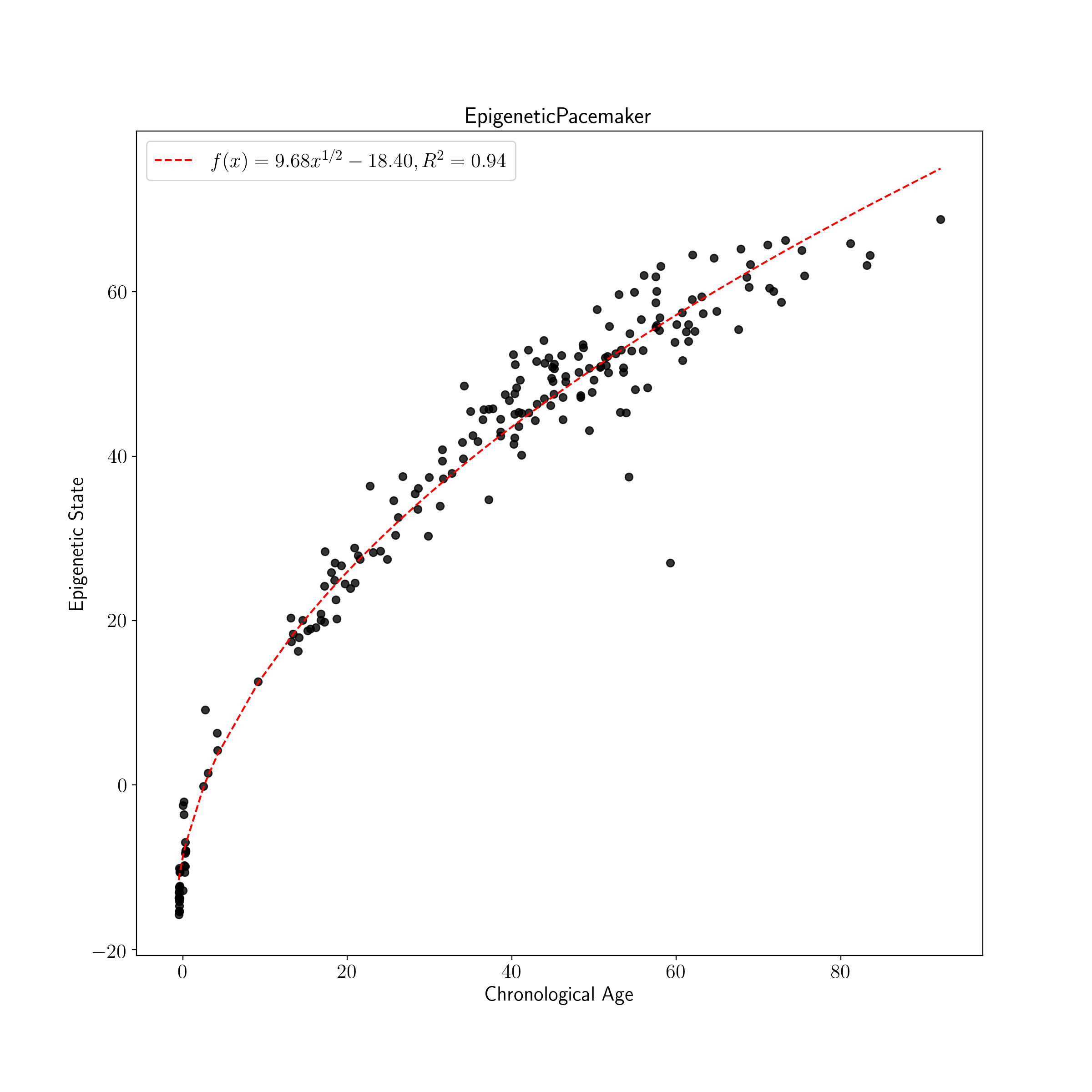
To visualize the results of the EPM a helper function is used. The function takes chronological ages and predicted EPM states as an input; then generates a scatter plot and trend line for the model.
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import rc
from scipy import optimize
import scipy.stats as stats
# use latex formatting for plots
rc('text', usetex=True)
def r2(x,y):
# return r squared
return stats.pearsonr(x,y)[0] **2
def plot_known_predicted_ages(known_ages, predicted_ages, label=None):
# define optimization function
def func(x, a, b, c):
return a * np.asarray(x)**0.5 + c
# fit trend line
popt, pcov = optimize.curve_fit(func, [1 + x for x in known_ages], predicted_ages)
# get r squared
rsquared = r2([1 + x for x in known_ages], func([1 + x for x in known_ages], *popt))
# format plot label
plot_label = f'$f(x)={popt[0]:.2f}x^{{1/2}} {popt[2]:.2f}, R^{{2}}={rsquared:.2f}$'
# initialize plt plot
fig, ax = plt.subplots(figsize=(12,12))
# plot trend line
ax.plot(sorted(known_ages), func(sorted([1 + x for x in known_ages]), *popt), 'r--', label=plot_label)
# scatter plot
ax.scatter(known_ages, predicted_ages, marker='o', alpha=0.8, color='k')
ax.set_title(label, fontsize=18)
ax.set_xlabel('Chronological Age', fontsize=16)
ax.set_ylabel('Epigenetic State', fontsize=16)
ax.tick_params(axis='both', which='major', labelsize=16)
ax.legend(fontsize=16)
plt.show()
Fitting EPM
The EPM is fit by calling the fit method. Following model fitting predicted ages are generated for the test data using the predict method.
from EpigeneticPacemaker.EpigeneticPacemaker import EpigeneticPacemaker
# initialize the EPM model
epm = EpigeneticPacemaker(iter_limit=100, error_tolerance=0.00001)
# fit the model using the training data
epm.fit(train_methylation_values[training_sites,:], train_ages)
# generate predicted ages using the test data
test_predict = epm.predict(test_methylation_values[training_sites,:])
# plot the model results
plot_known_predicted_ages(test_ages, test_predict, 'EpigeneticPacemaker')
Fitting Cross Validated EPM
The cross validated version of the EPM is fit using the same general process as the EPM following initialization with additional parameters. During fitting of the cross validated EPM an epigenetic state prediction is made for each sample when the sample is left out of model fitting. The reported EPM CV model is an average of model parameters across CV folds.
from EpigeneticPacemaker.EpigeneticPacemakerCV import EpigeneticPacemakerCV
# initialize the EPM model
epm_cv = EpigeneticPacemakerCV(iter_limit=100, error_tolerance=0.00001, cv_folds=10, verbose=False)
# fit the model using the training data
epm_cv.fit(train_methylation_values[training_sites,:], train_ages)
# generate predicted ages using the test data
test_cv_predicted_ages = epm_cv.predict(test_methylation_values[training_sites,:])
# get training sample EPM predictions during fold sample not used for training
train_cv_predicted_ages = epm_cv.predicted_states
# plot the training model results
plot_known_predicted_ages(train_ages, train_cv_predicted_ages, 'EPM CV Training Predicted Ages')
# plot the testing model results
plot_known_predicted_ages(test_ages, test_cv_predicted_ages, 'EPM CV Testing Predicted Ages')
| Training EPM States | Testing EPM States |
|---|---|
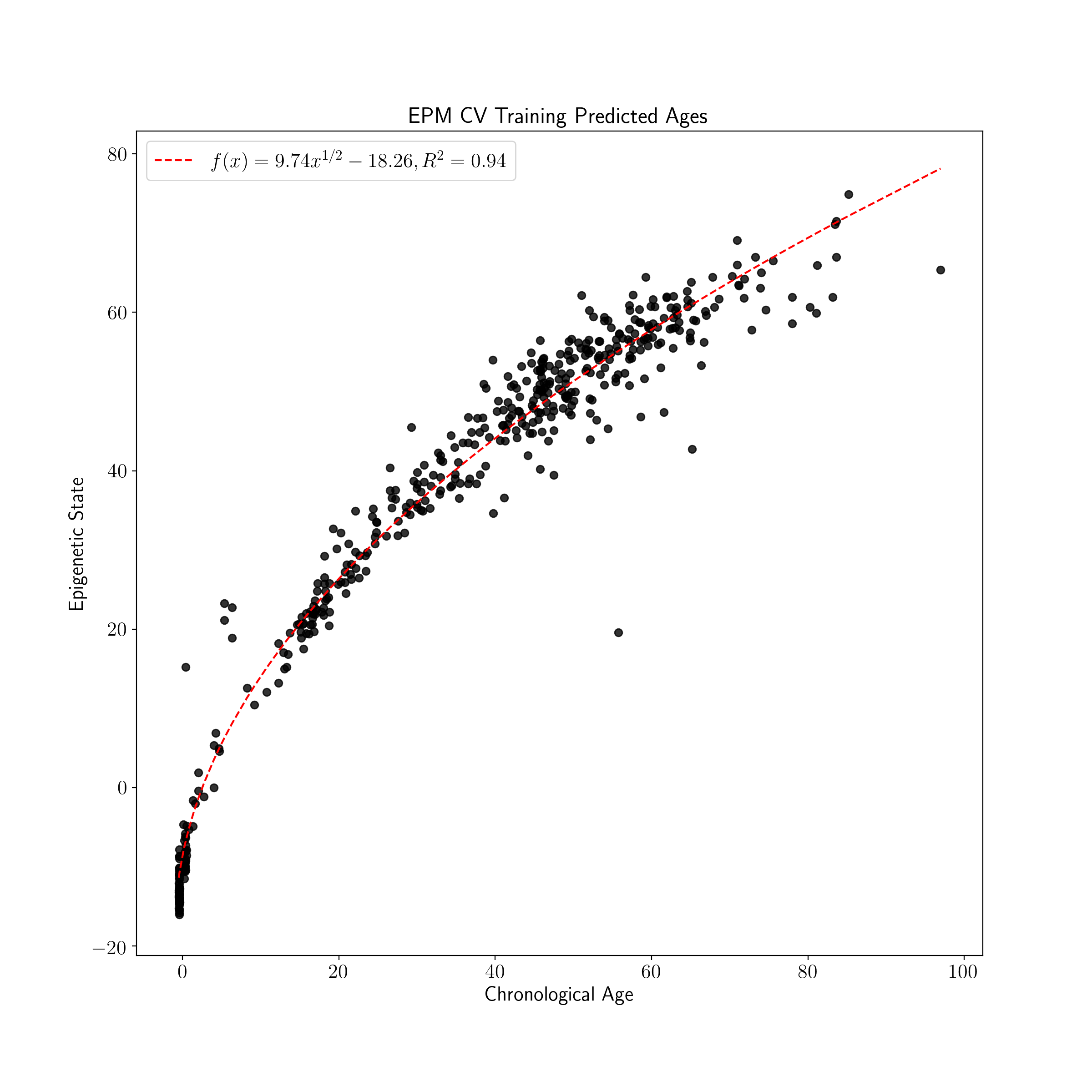 |
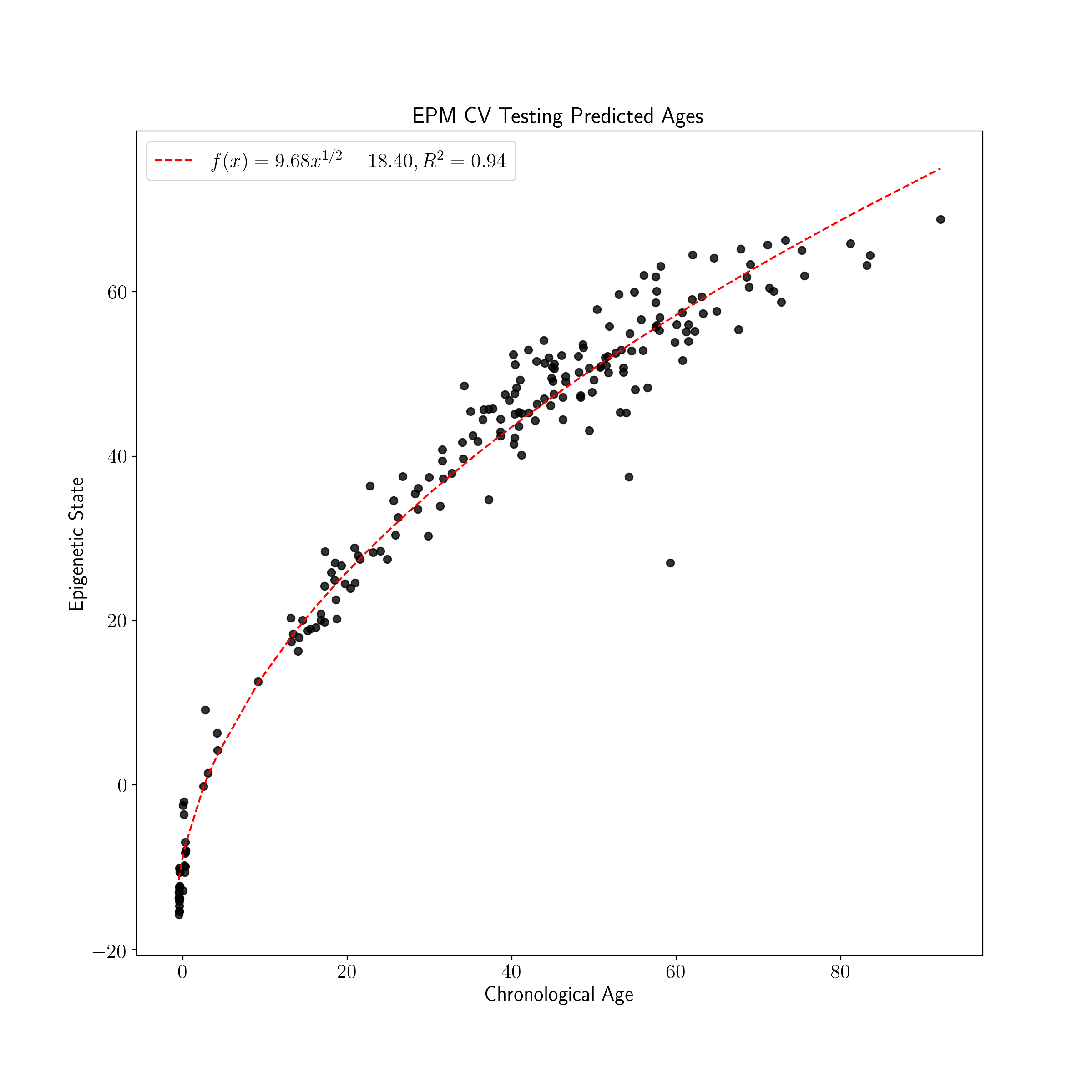 |